面试刷题31:分布式ID设计方案
本文共 673 字,大约阅读时间需要 2 分钟。
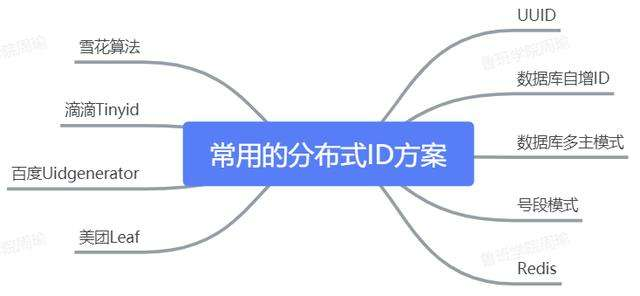
面试中关于分布式的问题很多。(分布式事务,基本理论CAP,BASE,分布式锁)先来一个简单的。
简单说一下分布式ID的设计方案?
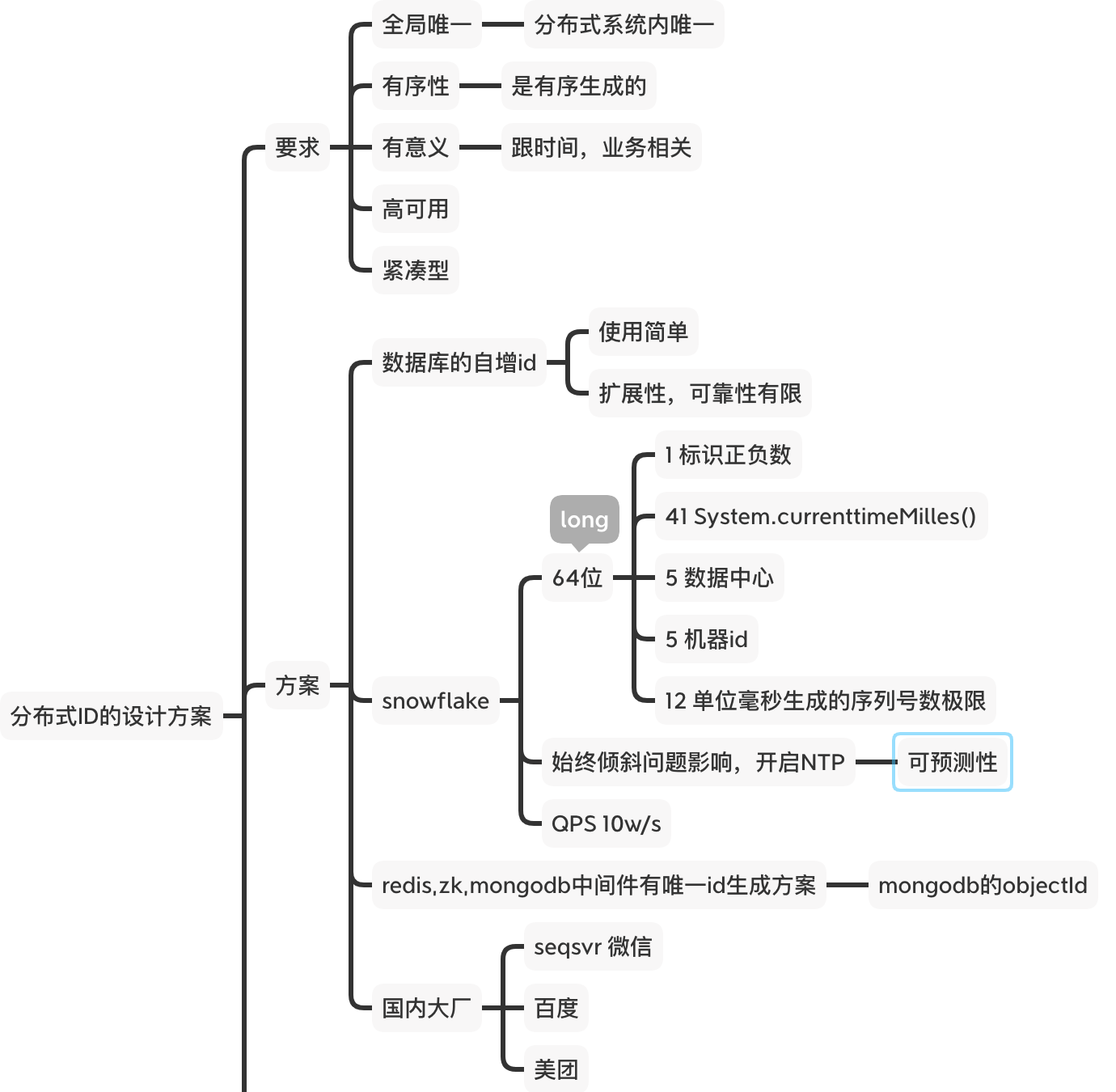
首先要明确在分布式环境下,分布式id的基本要求。
1, 全局唯一,在分布式集群下,不同的节点并发生成的分布式id要唯一;
2, 顺序性,分布式id是有序生成
然后给出分布式id的设计方案。
1, 基于数据的自增id生成分布式ID,使用比较简单,缺点是扩展性和可靠性有限;
2,基于 算法生成;
snowflake生成的分布式id是一个64位整数;位数标识如下:

1 标识正负
41位,一般使用System.currentTimeMilles()得到;
5 数据中心标识
5 机器ip标识
12 单位毫秒内可以生成的序数极限
snowflake的生成跟时间相关的使用的是System.currentTimeMilles(),跟冬令时没有关系。
分布式id的进一步要求
可靠性: 即高可用 紧凑性: 64位的整数比较长,不太紧凑,作为索引,存储不占优势。 有意义: 可以放入业务标识或者时间
snowflake的缺点
受时间影响:需要保证分布式集群的时间同步,即NTP ; 可以预测到:容易按照时间规律预测到,进而影响安全性;
小结
回答了分布式id的基本要求,已经常用方案。
原创不易,点赞关注支持一下吧!转载请注明出处,让我们互通有无,共同进步,欢迎沟通交流。 我会持续分享Java软件编程知识和程序员发展职业之路,欢迎关注,我整理了这些年编程学习的各种资源,关注公众号‘李福春持续输出’,发送'学习资料'分享给你!

你可能感兴趣的文章
poj 3863Business Center
查看>>
Android编译系统简要介绍和学习计划
查看>>
Android编译系统环境初始化过程分析
查看>>
user2eng 笔记
查看>>
DRM in Android
查看>>
ARC MRC 变换
查看>>
Swift cell的自适应高度
查看>>
【linux】.fuse_hiddenXXXX 文件是如何生成的?
查看>>
【LKM】整合多个LKM为1个
查看>>
【Windows C++】调用powershell上传指定目录下所有文件
查看>>
Java图形界面中单选按钮JRadioButton和按钮Button事件处理
查看>>
小练习 - 排序:冒泡、选择、快排
查看>>
SparkStreaming 如何保证消费Kafka的数据不丢失不重复
查看>>
Spark Shuffle及其调优
查看>>
数据仓库分层
查看>>
常见数据结构-TrieTree/线段树/TreeSet
查看>>
Hive数据倾斜
查看>>
TopK问题
查看>>
Hive调优
查看>>
HQL排查数据倾斜
查看>>